何为 APFS?
2016 年 WWDC 的时候,苹果甩出了一个名为 APFS 的文件系统,就是 Apple File System 的缩写。刚听到苹果又推出了一个文件系统的时候,我其实并没有特别惊讶,甚至感觉有些习惯了,因为自打苹果用上了 HFS 后,每隔一段时间就会来一个变种,甚至说每一个设备可能都会有一种特殊的 HFS(据说 iOS 里面使用的 HFS 也是个独特的变种,连 macOS 的同学都不知道他们自己搞了一套),后来又有了 HFS+。
不过按照苹果的习惯,一旦一个技术为了适应苹果的产品而被改来改去,杂乱无章的时候,就意味着在不久的将来肯定会有个全新的技术来替代它,例如早些年用 clang 替换掉了 GCC,现在正在用 Swift 替换 Objective-C。
在 iOS 10.3 发布之前,我完全没有仔细地去了解过这个玩意儿,直到 iOS 10.3 beta 版出来后,大家惊呼 APFS 现身带来了更多的可用空间,我才意识到这个技术可能又是一个苹果新造的轮子。
果不其然,在和 HFS 抗争多年后,苹果终于发现这垃圾玩意已经没有改的价值了,所以另起炉灶,重新搞一套。传闻 APFS 项目中负责人为了保证不受其它已有文件系统的影响,不去看任何一个文件系统的实现原理和机制,从零开始,针对苹果现有的设备形态,打造的一个全新的文件系统。
在苹果官网 APFS 的介绍页,介绍了它的一些主要特性:
Apple File System is a 64-bit file system supporting over 9 quintillion files on a single volume. This state-of-the-art file system features cloning for files and directories, snapshots, space sharing, fast directory sizing, atomic safe-save primitives, and improved filesystem fundamentals, as well as a unique copy-on-write design that uses I/O coalescing to deliver maximum performance while ensuring data reliability.
简单来说,主要还是从效率和安全性方面做了很多改进。
主要特性
Clones
通俗点来讲,就是平时我们拷贝文件。按照我们传统思维来讲,拷贝一个文件到另一个地方还需要在磁盘上占用相同空间,并且视文件大小还会有相应的拷贝时间(例如拷一个 1GB 左右的大姐姐影视作品到别的地方,可能就需要另外占用 1GB 空间,并且还需要差不多 1s 左右的拷贝时间)。
但是在 APFS 下,一个 clone 操作基本上是瞬间完成,不管大小,并且也不会额外占用磁盘空间。
那它是咋做的呢?其实有点像是我们平时写代码时用的浅拷贝,仅仅是创建了个副本指针,指向了相同的一块区域。
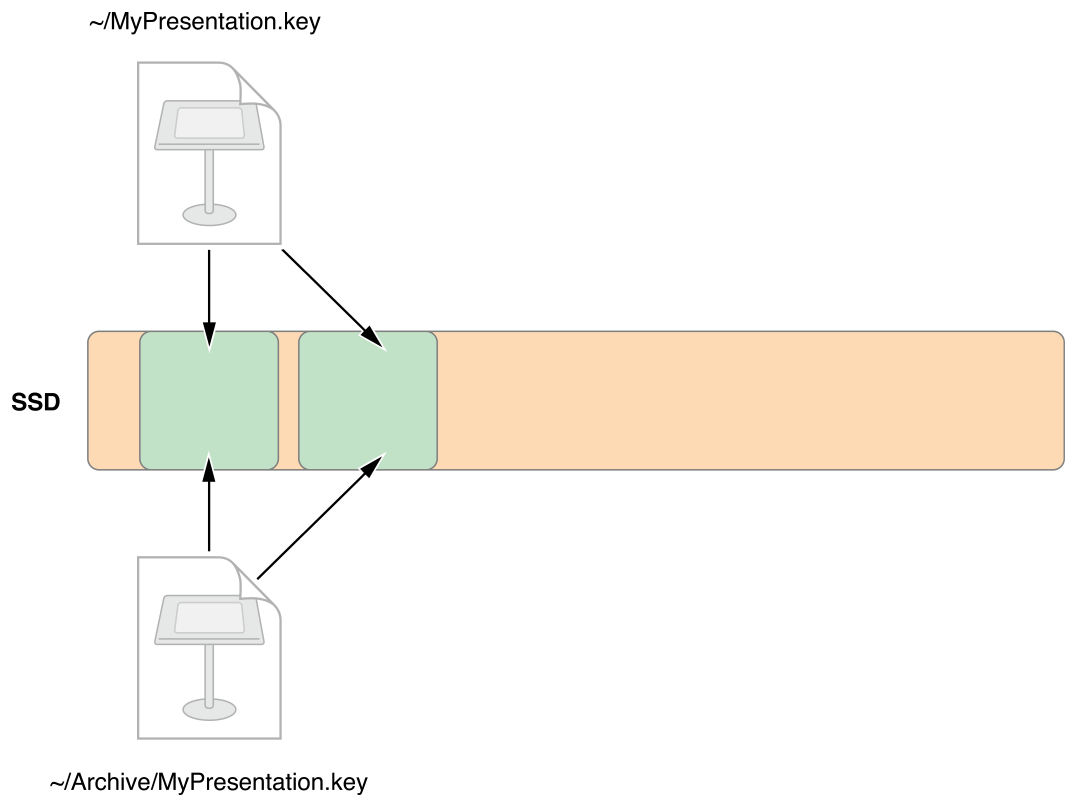
可是问题来了,我们都知道,在浅拷贝操作后,如果内容发生了变更,那么所有指向这块内存的变量都会跟着改变,而在文件系统中如果这么做,那和链接有什么区别?我们希望的就是保留变更啊。好吧,你们要不同,APFS 就仅仅保留了不同。
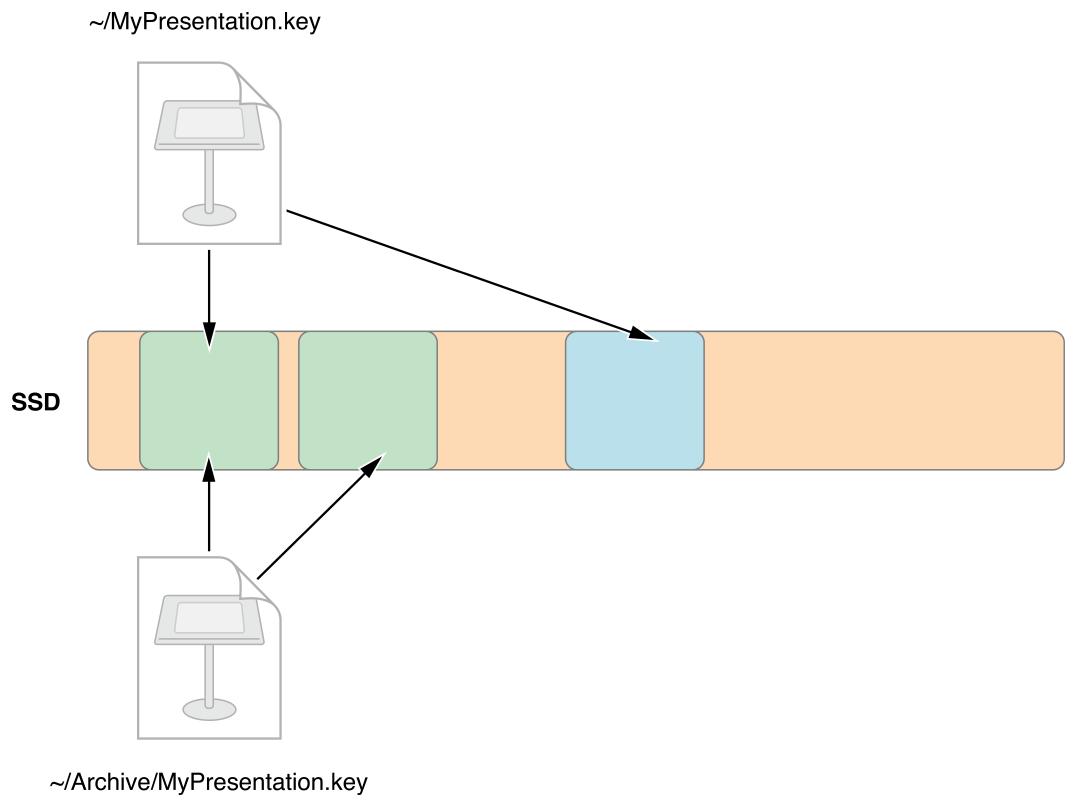
听起来有点和 Git 的一些做法类似啊。
Snapshots
快照通常情况下是一种用于备份的方式,操作系统同时可以使用快照快速还原到某一个时间点。有别于传统的备份,快照不管是从时间还是从空间占用都不大。
APFS 的快照也类似,不过从介绍来看,和传统的快照类似,只记录 diff,所以说创建了多个快照也不会特别大。
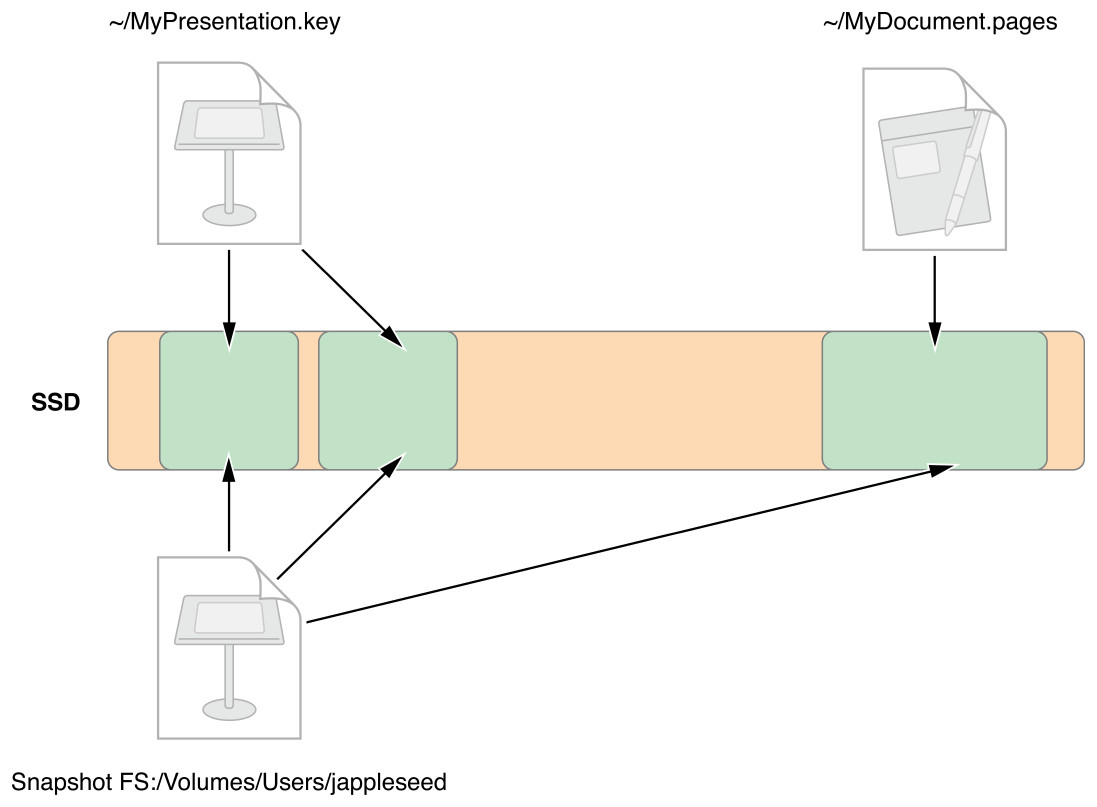
得益于 clone 的思路,创建快照也是一个简单的“指针”创建和引用,由于速度快,创建快照可以在不打断用户操作的前提下对数据进行备份
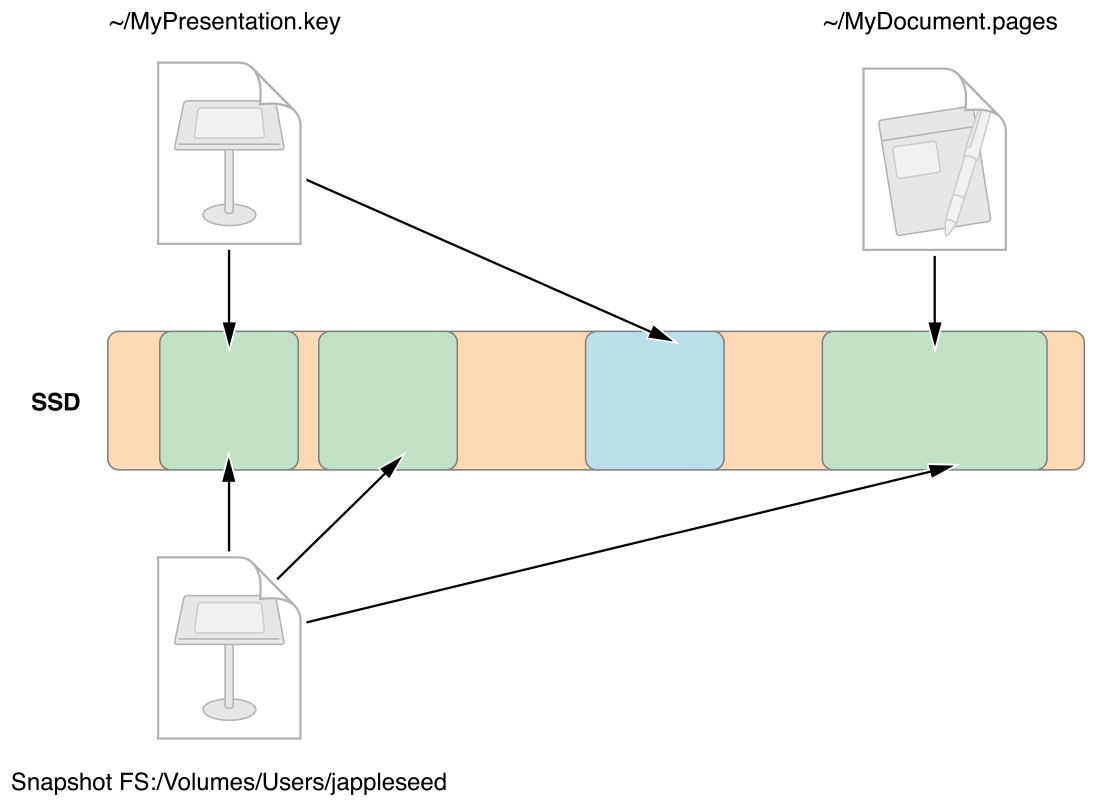
不过不巧的是,由于 APFS 不支持硬链接,还不支持现阶段的 Time Machine,所以为啥只有 iOS 现在用上了 APFS 而 macOS 还没有(其实想用也是可以用的,只不过限制多多,想必苹果可能也没有做好软件层面的适配),想必有一部分是这个原因。
Space Sharing
这个技术就有点厉害了,回想下我们在用 Windows 的时候,如果不加控制或者在一开始给系统盘分配的空间不多的话,会在使用一段时间后收到系统警告,告诉你系统盘空间不足。
通常面对这样的情况,我们可能会尝试删一些文件或者软件啊,高端点的玩家可能还会调整下磁盘分区,再高端点的玩家可能直接就选择重装系统了。完后为了防止再出现这样的问题,可能就会不再系统盘装软件放文件之类的,但是这样来说可能有会产生其他奇奇怪怪不是特别好的问题,总之非常头疼。
虽说用 Mac 后就没有再分过区,但是 Space Sharing 这项技术解决的就是上述问题。
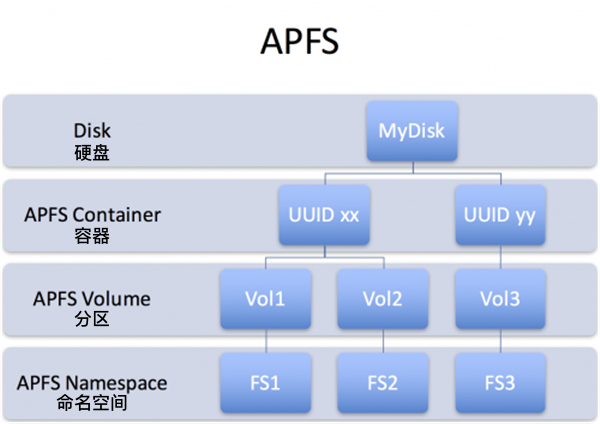
Space Sharing 允许多个文件系统在物理卷上共享相同的底层可用空间。与为每个文件系统预先分配固定数量的空间的刚性分区方案不同,APFS格式的卷大小可以在不重新分区的情况下增长和缩小。
APFS 容器中的每个卷都会给操作系统报告相同的可用磁盘空间,这相当于容器的总可用磁盘空间。例如,对于分区A(已用 10GB)和分区B(已用 20GB)的容量为 100GB 的 APFS 容器,显示的 分区A 和 B 的可用空间均为 70GB(100GB - 10GB - 20GB)。
Encryption
苹果在安全方面一向比较严格,想想 FBI 为了给一个 iPhone 5c 磁盘解密从而拿到里面的数据,威逼利诱苹果帮忙,结果苹果却以除了用户谁都解不开为由拒绝,尽管到后来还是被解开了,但是从历年来有关苹果设备出现的安全问题的情况来看,因为设备和技术原因的基本没有。
而随着 macOS 上 FileVault 的出现,全盘加密几乎成了 macOS 的标配。想想几年前还在用 Windows 的时候,换了块硬盘,拿着老硬盘放到移动硬盘盒里就能当移动硬盘使用继续读取原来的数据,虽说 Windows 也有全盘加密的技术,但是从用户体验的角度来讲,苹果无疑是让你在不知不觉中就被保护了起来,这倒让我想起了一句话:真正的科技是让你感受不到它的存在。
APFS 里面,安全是它的设计基础,而针对不同的设备,APFS 加密方式也不尽相同。APFS 为容器中的每个卷提供了以下三种加密模型:
- 无加密
- 单键加密
- 多键加密
其中多键加密最为安全(这不废话么),官网介绍说,哪怕在你的设备物理安全受到威胁并且获取到访问权限,也不能解开 APFS 保护下的磁盘数据。其实上面这句话我没怎么理解,但是猜测可能是类似 macOS 的登录密码被破解了,但是磁盘数据仍然不会被解密,具体的还是日后再研究吧。
得益于它加密功能的实现,我们以后想要删除数据就没必要反复覆盖磁盘数据了,直接删除掉密钥就 OK 啦,相较于前者,简单快速。
Crash Protection & Atomic Safe-Save
作为文件系统,最重要的就是要保证数据的安全,而在我们平时日常使用过程中,难免会遇到一些突发情况,导致数据错误甚至丢失,所以文件系统作为操作系统和磁盘中间管理数据的系统,强大的数据安全保护性是一个很重要的功能。
APFS 利用 copy-on-write 这项技术,可以在数据真正完成更新后再写入,期间如果发生了异常中断,诸如 Crash,那么也不会影响原有数据。而这种原子性操作,对于用户而言,只有两种状态——完全更新和啥都没变,没有了中间状态就会减少出现异常情况的可能性。
从正常的使用来看,我们操作过程中可能出现的问题,APFS 已经做了保护,并且有别于其它文件系统的数据一致性复杂校验,APFS 原子性操作从某种程度上是提高了效率。
不过提到数据校验,我从一些文章中发现,苹果的校验机制挺有意思,只会校验元数据,而用户数据则不管,WWDC 上 APFS 工程师说到,之所以这么做,是因为元数据相较于用户数据更重要,但是校验成本低,并且所有苹果设备中都有 ECC 纠错保护,加上 NAND 的冗余数据检验纠错,已经足够了。其实最有意思的是,苹果工程师对自己的设备很有信心,认为他们的设备通常不会遇到数据错误,设备本身误码率已经相当低了。
至于这种信心从何而来我不得而知,不过从专门用于数据存储阵列的 ZFS 文件系统都可能会出现数据错误,并且它们的硬件可是上百万美元级别的,那么相较于 iPhone 和 Mac 中的 TLC 芯片,如何保证数据不出错?
Performance
性能可能是 APFS 另一个重要特性,正是因为苹果认为 HFS 不能够适用于 SSD,才重新开发 APFS 并着重优化 SSD 的存储。
SSD 和 HDD 在本质上有着很大的差别,除了 SSD 不需要寻道以外,它的存储方式也是不一样的,例如为了保证 SSD 整体的寿命,闪存主控会把写入的数据均匀分散在各个块中,因为 SSD 内的闪存的寿命是由写入次数决定的。而和上层,也就是文件系统层的交互,则是通过一个类似于虚拟内存一样的,被称作 FTL 的东西负责处理的,它会在块地址和真正存储位置中间建立个映射关系。
除此之外,SSD 有别于 HDD 还有个点,就是空间回收,HDD 通常的做法就是,这块数据不要了,我就标记为这块是空闲空间,以后用到的话再覆盖掉就好了,没必要删,所以说如果我们想要恢复数据,是一件挺容易的事情。而 SSD 则没办法这样做,因为在 SSD 中,只有空数据块才可以直接执行写入操作,而非空的要先擦除掉才能写入。
这样看来,SSD 和 HDD 的区别仅仅是多了一步擦除操作而已,但实际上并非如此。在 SSD 中,数据存储的最小单位是页(page),一个页的大小一般是 4KB,若干个页面又被组合成块(block),一个块的大小一般是 512KB。由于硬件方面的限制,SSD 单独对某个页面进行读写的操作,但擦除操作却只能对整个块进行,也就是说,一旦擦除就必须一次性擦除整个块。想想看,如果操作系统要让 SSD 改写某个页面的数据,SSD 需要执行怎样的操作呢:
- 将要改写的目标页面所在的整个块的数据读取到缓存。
- 在缓存中修改目标页面的数据。
- 对整个块执行擦除操作。
- 将缓存中的数据重新写入整个块中。
一个简单的 4KB 操作可能就需要把整个 512KB 的块都操作一遍,虽说 SSD 读写速度快,但这样无谓的折腾也是挺影响效率的。也正是因为这样的原因,SSD 的主控中通常会提供一个 TRIM 的命令,操作系统在删除文件时可以向主控发送 TRIM 命令告诉它哪些数据不需要了,主控拿到命令后不着急删除,而是定期 GC 一下。
不同类型的主控所提供的 TRIM 也不太一样,APFS 虽说也支持了 TRIM,并且做出了一些改进,但是按照苹果的风格,应该还是先支持自家产品使用的 SSD。
另外,APFS 也通过 I/O QoS(服务质量)对不同的数据操作请求分优先级,将用户可以立刻感知到的操作优先级提高,后台任务就可以放放。听起来和 iOS 里面的 UI 操作类似,这种高用户体验的小设计苹果也是玩的很转啊。
总结
当然还有例如稀疏文件支持,快速目录大小调整等特性,但是也存在着我看来不是特别靠谱的地方,就像上面我们提到的数据校验那一块,看起来有些想当然。不过针对现阶段硬件进行的软件层面的优化,肯定会比 HFS 这种杂乱老旧并且臃肿的文件系统要好的吧。毕竟在这个世界上,能够和苹果比软硬件结合开发,应该也没谁了吧。
从 iOS 10.3 可以显而易见的看出优势,哪怕只是多了几个G的可用空间,也是棒棒哒!(不过你们难道没发现通过 iOS OTA 升级无损切换文件系统其实也是一件很厉害的事么?不过从刚才我们分析 copy-on-write 这项技术来看,应该也不会有啥问题。)
虽说 macOS 目前还是不能从 GUI 上找到什么 APFS 的痕迹,但是可以通过一些命令行方式创建一个 APFS 卷(分区)。
1 | hdiutil create -fs APFS -size 1GB foo.sparseimage |
不过要注意的是,现在的 macOS 的 Time Mechine 并不兼容 APFS,FileVault 也是不兼容的,最主要的是,目前正式版本 macOS 10.12.4 是不支持 APFS 的分区当作启动分区的。
所以简单来说,体验一下 APFS 没啥问题,想日常使用,就算了,等 macOS 什么时候兼容 APFS,应该会是有很大程度的用户体验提升吧。
虽说苹果直接扔掉了 HFS 开发了 APFS,但是我感觉当前版本的 APFS 应该不会成为一个主流的文件系统,首先一点就是苹果还没有开源,至于到底开不开源不得而知。另外这种针对 SSD 专门开发的文件系统,是否对于 HDD 有支持,我们也不清楚。处于自家生态链的考虑,抛弃掉32位设备的支持,也会让它在一段时间内只会出现在苹果的设备上。
存在一些遗憾也在所难免,不过作为用户能够更好地体验苹果产品也是挺爽的。

